
Stop Renting Your Customer Data. Start Owning It.
A warehouse-first CDP built on RudderStack — client + server-side tracking unified, a canonical customer profile (RCU) inside your warehouse, and reverse-ETL activation back to every channel. No vendor cloud holding your data hostage.
Your CDP Is Probably Costing You Twice.
Once in licence fees, once in opportunity cost. Here's what a fragmented or rented CDP is silently doing to your activation right now:
Vendor Lock-In on Your Own Customers
Classical CDPs route every event through their cloud. You pay forever, you can't see the raw data, and migrating off them is a 6-month project. The data is yours on paper — and theirs in practice.
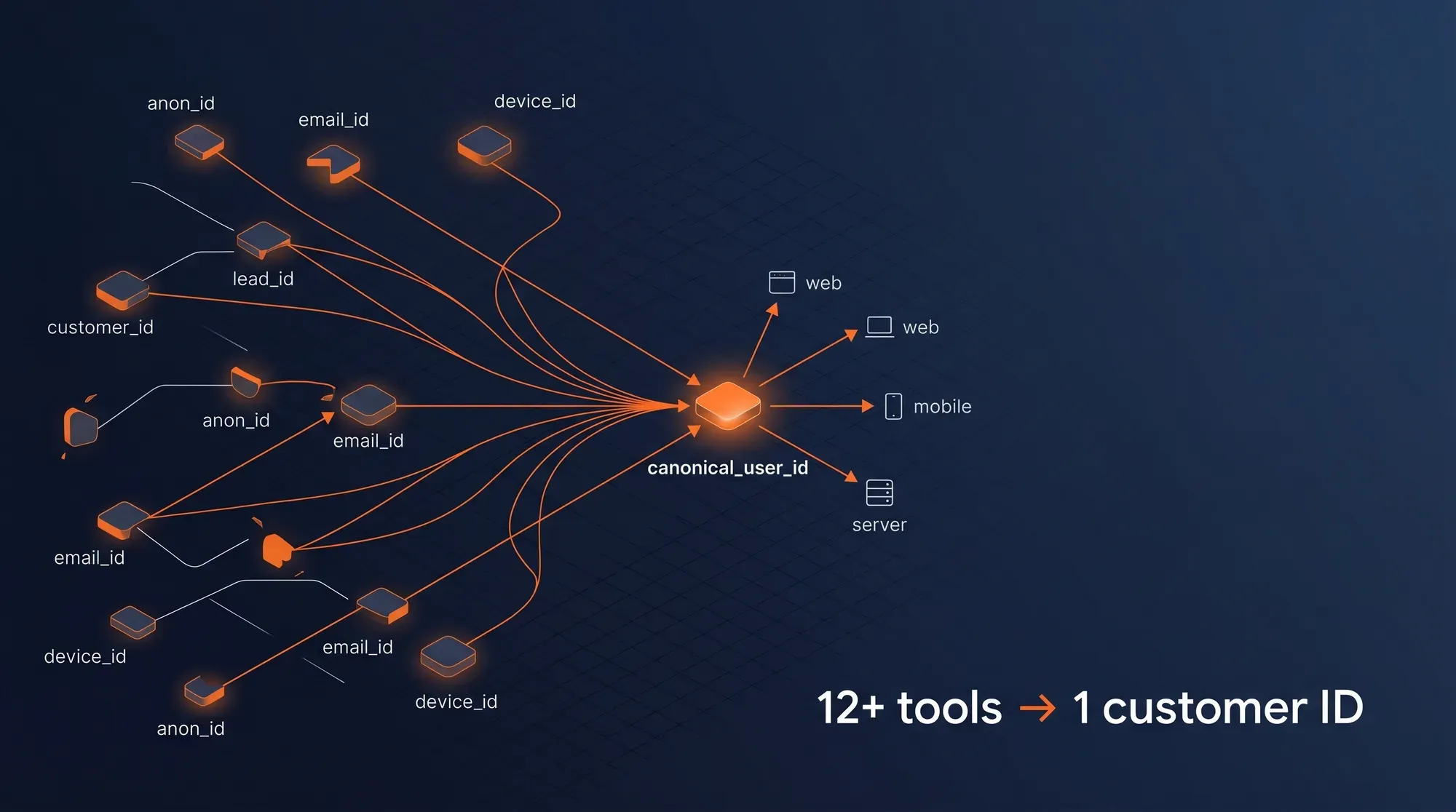
Black-box pricing · 6+ months to exitFragmented Identity Across Every Tool
The same human is anon_id 1234 on the website, customer_id 5678 in Shopify, lead_id 9012 in HubSpot, and email_id ABC in Klaviyo. None of them know about each other — your "personalization" is sending the wrong message to the wrong person.
5+ disconnected user IDs per customerOne-Way Data, Zero Activation
Analytics flows in, but nothing flows back out. Your warehouse holds gold, but Meta still gets last-click pixel events, Google Ads still optimizes on form-fills, and Klaviyo still sends to "all customers" because there's no segment layer between data and action.
Data in: yes · Data out: never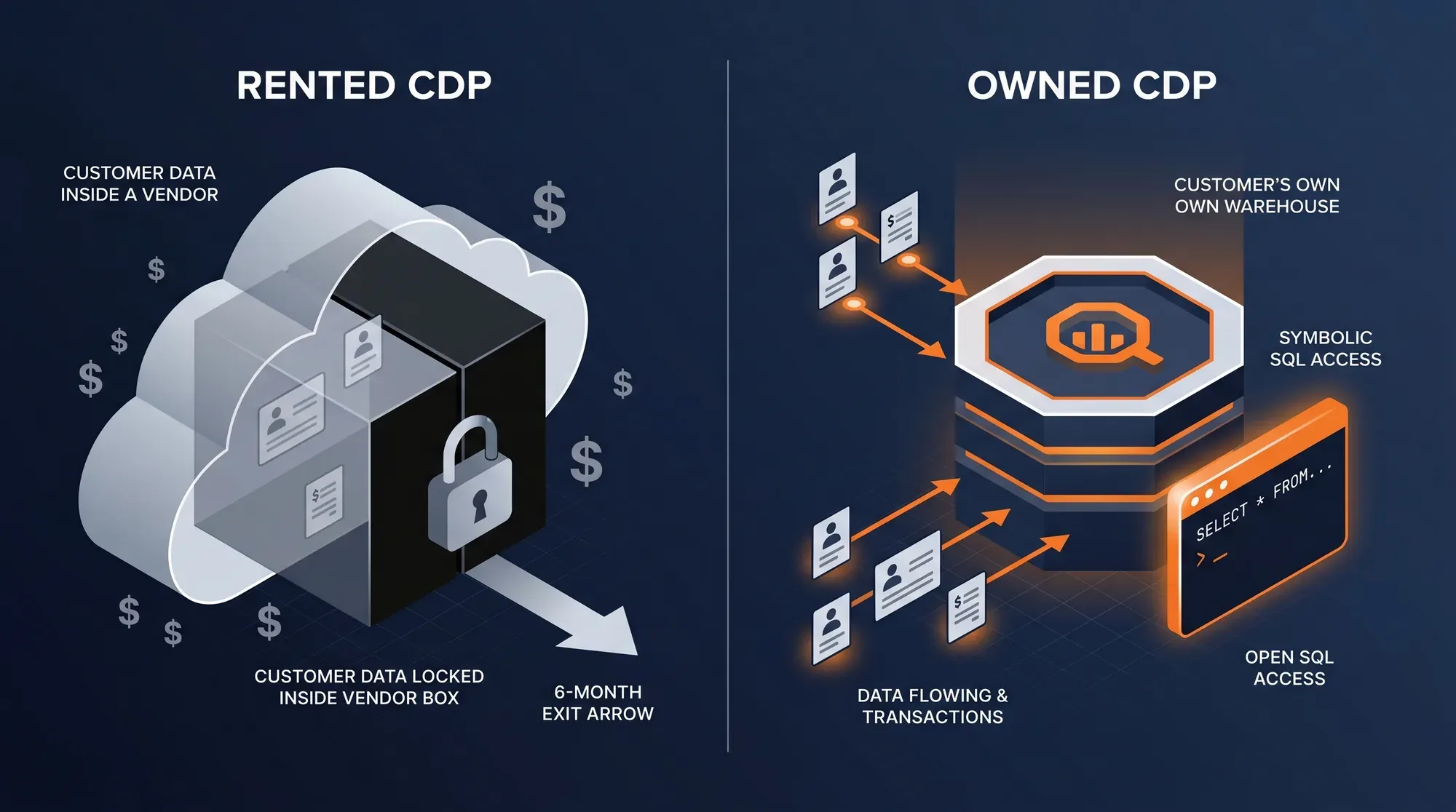
Four Pillars of a CDP You Actually Own
We don't resell a SaaS dashboard. We build a CDP architecture where you control every layer — collection, identity, governance, and activation.
Unified Tracking — Client + Server Side
RudderStack SDKs run in the browser, in mobile apps, and on your servers — all writing to the same event schema and the same identity graph. Every event is validated against a JSON schema before it lands. No more "the web is tracked one way, the backend another, and they don't match."
Impact → Single source of truth · Schema-validated events · Web + mobile + server unified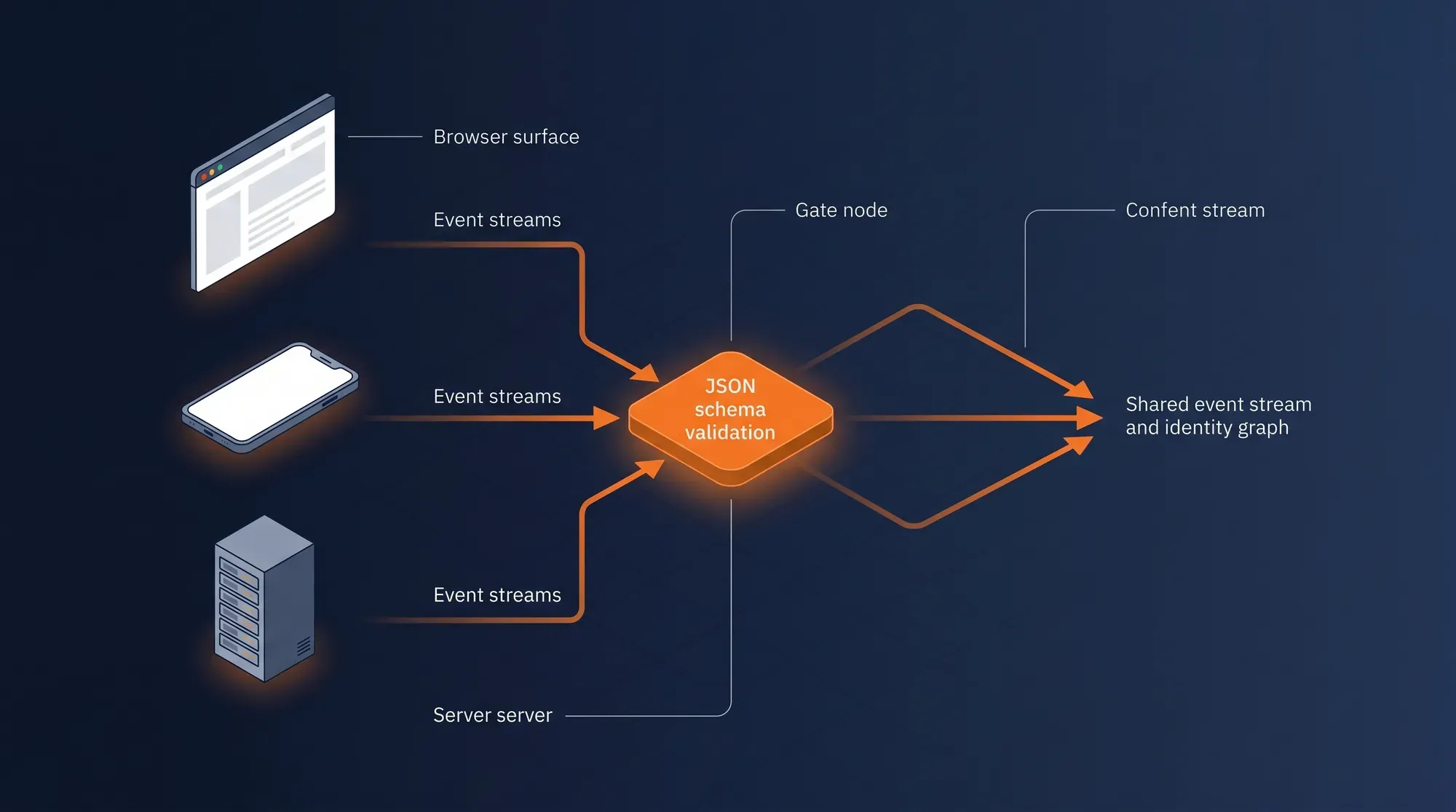
Warehouse-First Architecture
RudderStack writes raw events directly into your BigQuery — not its cloud. dbt models on top build the canonical customer profile. You own every row. If you ever want to switch CDP vendors, the warehouse stays — there is no migration to do because the data was always yours.
Impact → 100% data ownership · Zero vendor lock-in · Open SQL access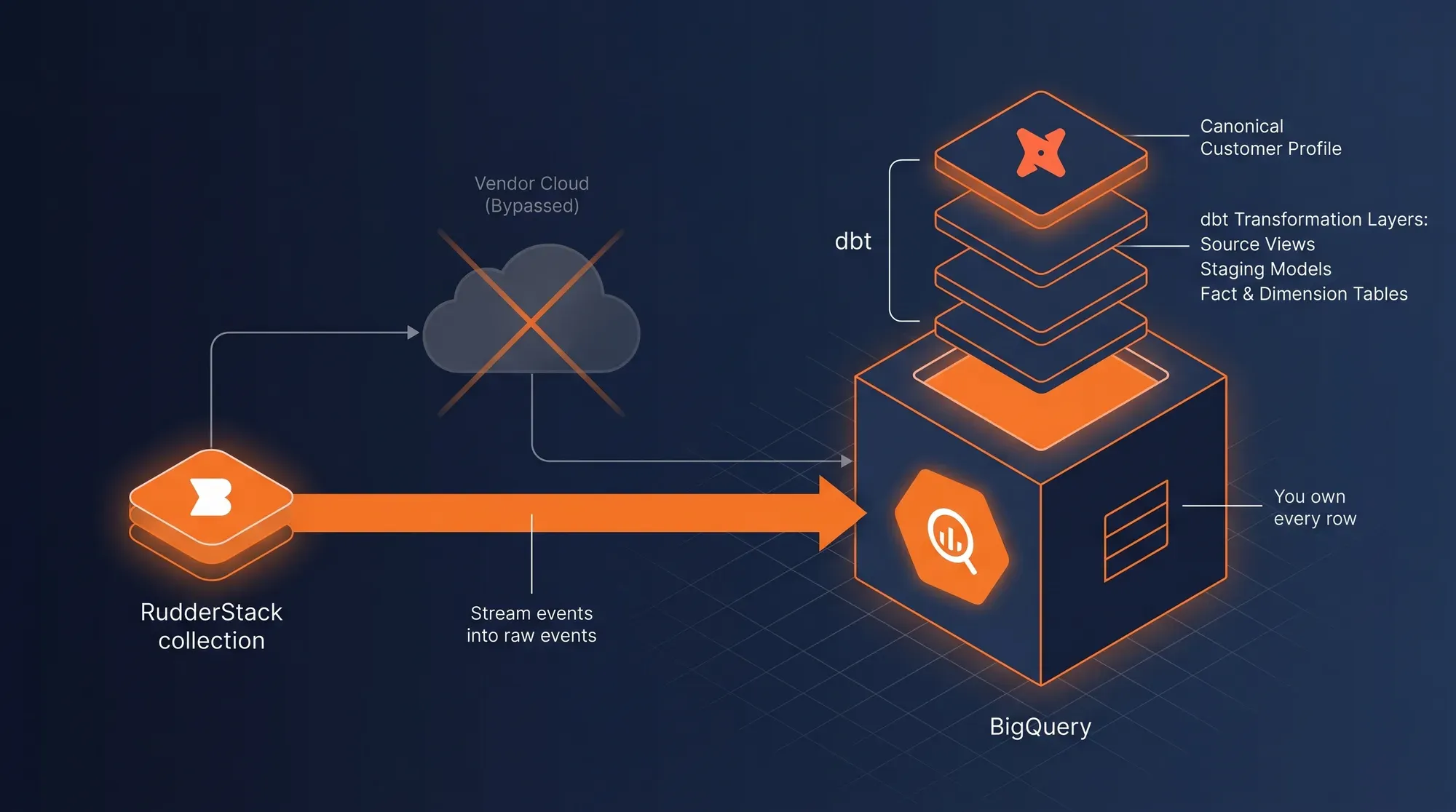
RCU / Customer 360 — Identity Resolution
Identity stitching combines deterministic matches (email, phone, customer_id — hashed and matched exactly) with probabilistic fallback (device graph, session continuity, IP + UA fingerprint). One canonical_user_id propagates everywhere downstream — your CRM, your dashboards, your activation channels all agree on who is who.
Impact → One profile per human · Anonymous → known stitched · Consent-aware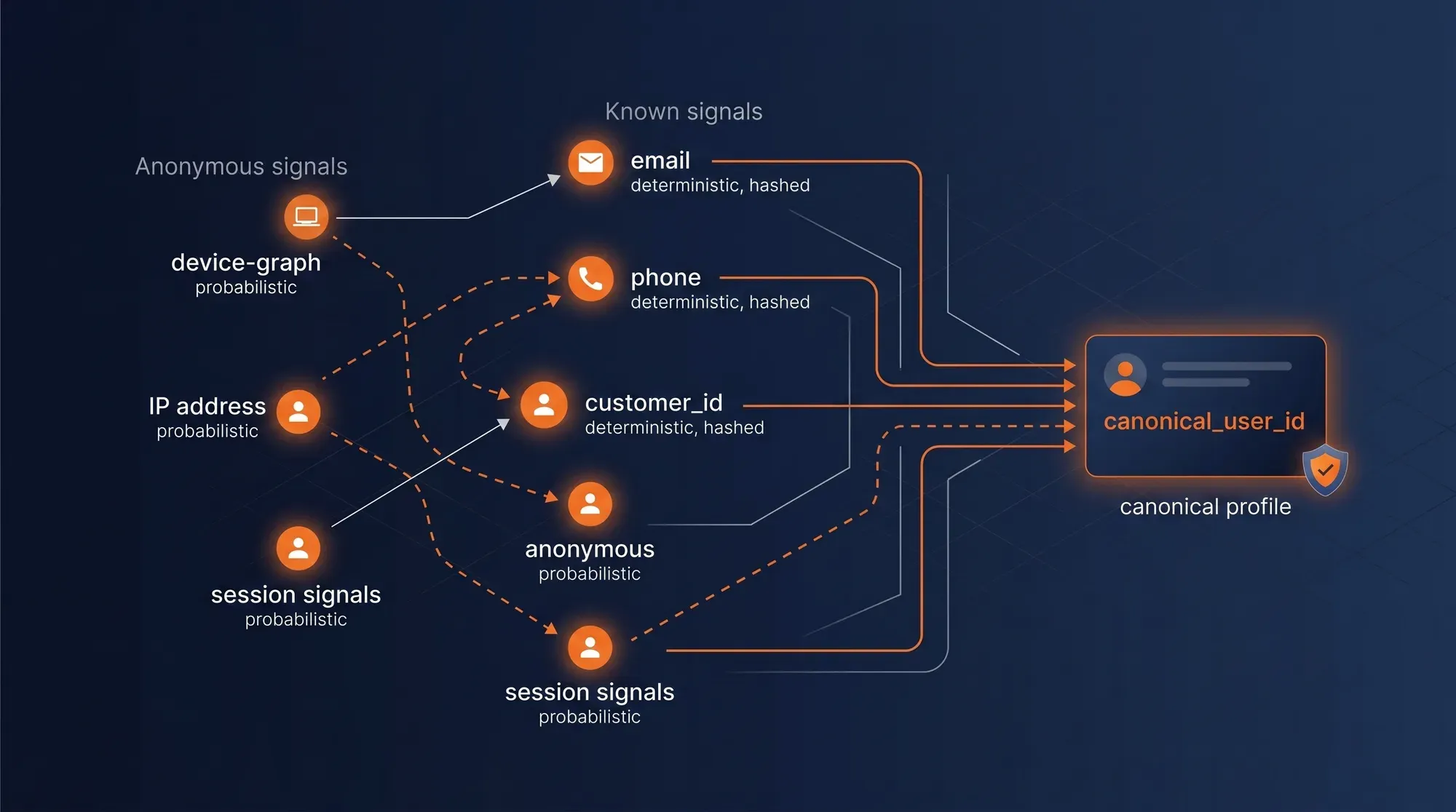
Reverse ETL — Activation Back to Every Channel
Segments are defined as SQL queries against your marts: "customers with RFM score 5/5/5 who haven't bought in 60 days". RudderStack Reverse ETL (or Hightouch / Census as alternatives) syncs them on a schedule into Meta Custom Audiences, Google Customer Match, Klaviyo lists, HubSpot lifecycle stages, Mixpanel cohorts. Consent is enforced before any row leaves the warehouse, PII is hashed automatically.
Impact → SQL-defined audiences · Consent-respected · One definition, every channel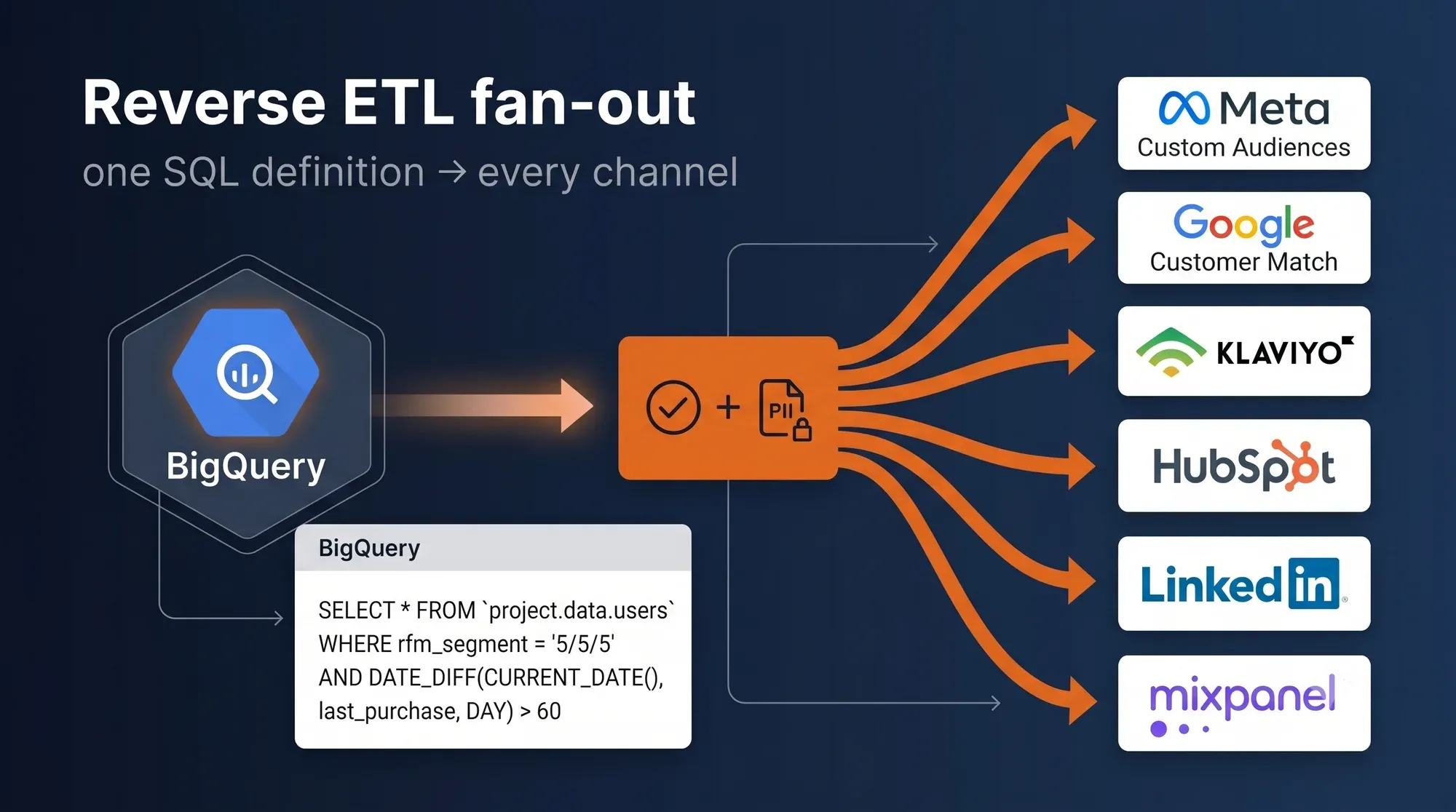
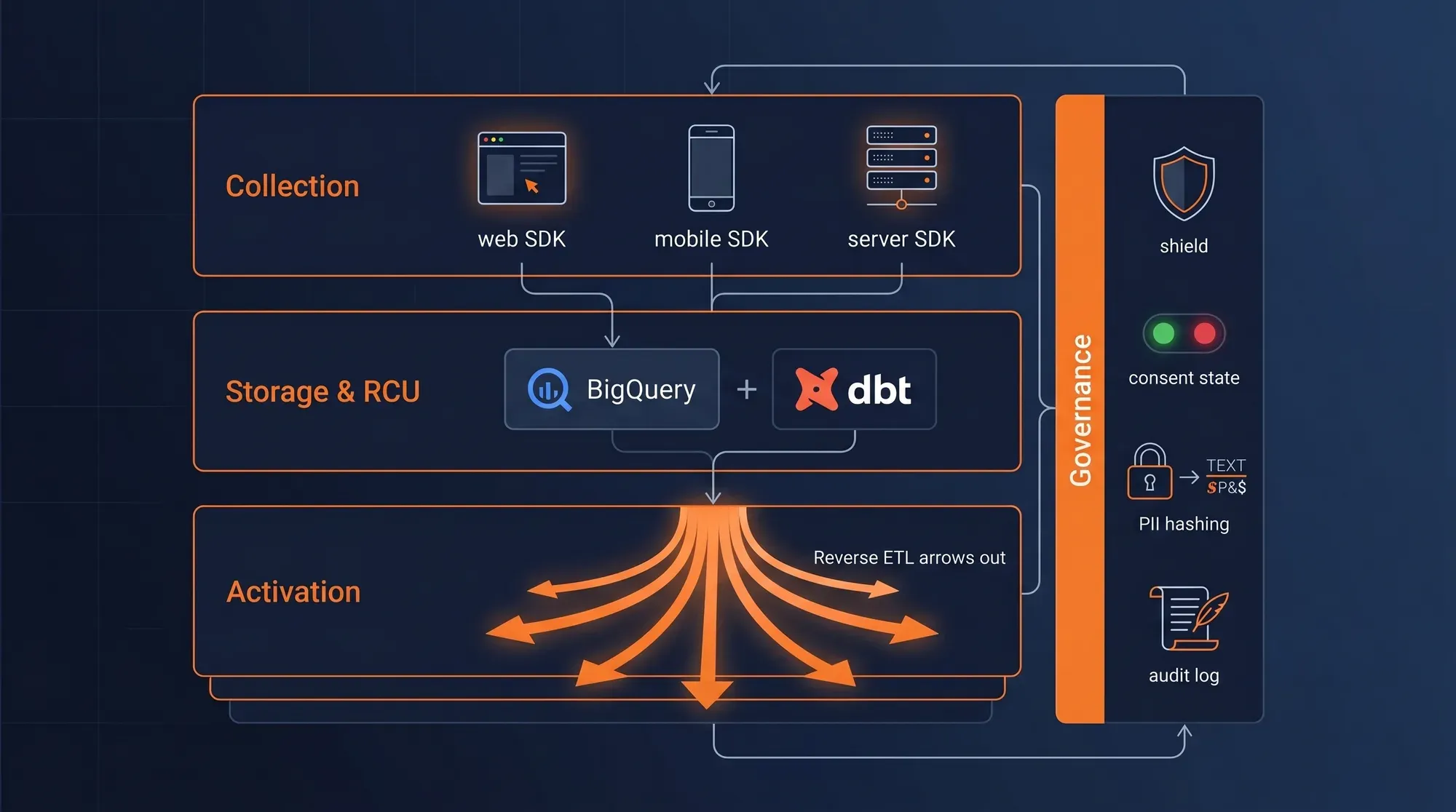
The Four Layers of a Warehouse-First CDP
RudderStack is the default at every layer where it makes sense — same vendor for collection and activation cuts integration debt. But each layer is still an independent choice.
Collection
Capture every event from every surface — web, mobile, server, legacy. One schema, one identity graph.
- RudderStack JS SDKWeb · client-side
- RudderStack Mobile SDKsiOS · Android · React Native
- RudderStack Server SDKsNode · Python · Go · Ruby
- HTTP sourceFor legacy or proprietary systems
Storage & RCU
Raw events land in your warehouse. dbt models build the canonical customer profile on top. You own every byte.
- BigQueryDefault · warehouse-native sink
- dbt ModelsIdentity resolution in SQL
- PostgresAlternative for small volumes
Activation
Segments defined in SQL, synced to every operational tool on a schedule. Consent and PII handling baked in.
- RudderStack Reverse ETLDefault · same vendor as collection
- HightouchAlternative · specialized Reverse ETL
- CensusAlternative · git-native workflow
- Native CAPI integrationsMeta · Google · LinkedIn · TikTok
Governance
Every event tagged with consent state. PII hashed before leaving the warehouse. Every sync audited.
- Consent state per channelGDPR / ePrivacy compliant
- PII hashing built-inSHA-256 at the source
- Audit log per eventDefensible to regulators
- Subject access workflowSAR / DSAR exports automated
Our Implementation Methodology
A proven 6-step process — from event schema to live reverse-ETL activation, in 8 to 12 weeks.
Event Schema Design
3–5 daysWe define the canonical event spec (track, identify, page, screen, group) before any code is written. Compatible with the Segment specification so you stay vendor-portable from day one. Documented in a single source-of-truth — no more "what does product_viewed actually mean?".
RudderStack Deployment
2–4 daysSelf-hosted on Coolify / Hetzner for full data sovereignty, or RudderStack Cloud for fastest time-to-value. Workspaces, sources, and destinations provisioned. Warehouse sink wired to your BigQuery from the first event.
SDK Instrumentation
1–2 weeksWeb SDK installed and wired to the existing dataLayer. Mobile SDKs added if applicable. Server SDKs for order completion, refund, subscription events from your backend — these never get blocked, never get sampled.
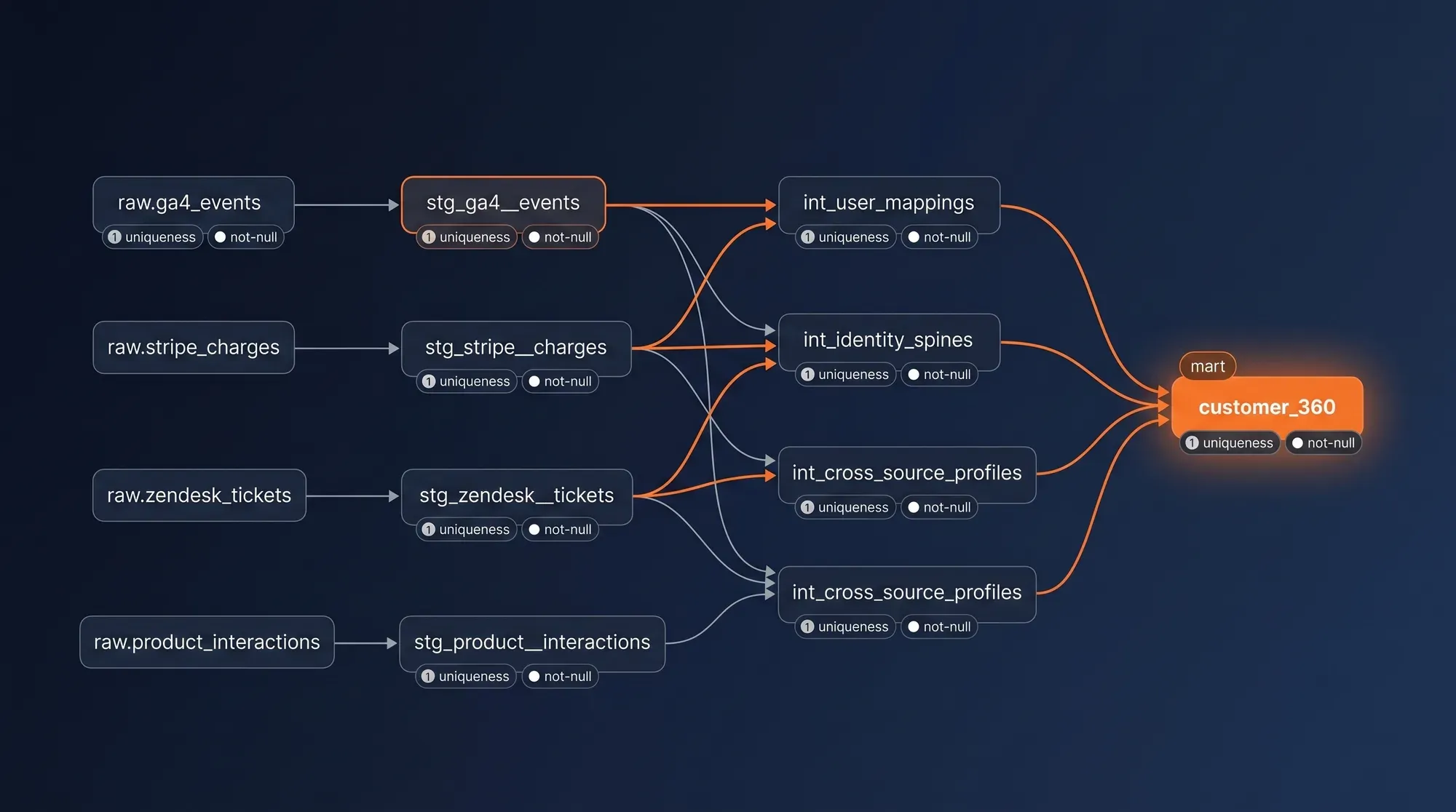
Warehouse Sink + dbt RCU Models
2–3 weeksRaw events flowing into BigQuery. dbt staging models normalize per source. Intermediate models stitch identity (anonymous → known). Mart layer exposes the canonical customer_360 table: every known signal about a person in one row, updated continuously.
Reverse ETL Segments
1–2 weeksAudiences defined as SQL queries against the mart layer. Synced to Meta Custom Audiences, Google Customer Match, Klaviyo, HubSpot, LinkedIn Matched Audiences. Each sync respects consent state and hashes PII before transmission.
Consent & Audit Setup
3–5 daysConsent state tracked per channel per profile. PII hashing verified end-to-end. Audit log enabled for every reverse-ETL sync. SAR / DSAR export workflow tested. Documentation handed over. Runbook for incident response.
What's included
RudderStack Provisioned
Self-hosted on Coolify (full data ownership) or RudderStack Cloud (zero infra). Workspaces, sources, destinations, transformations — all configured and documented.
Event Schema + JSON Validation
A canonical event taxonomy in line with the Segment spec. Schema validated at the edge — bad events are rejected before they pollute the warehouse.
BigQuery Sink + dbt RCU Models
Raw events streaming into your warehouse continuously. dbt models stitch identity into a canonical customer_360 table — the single source of truth your team queries.
5–10 Reverse ETL Audiences Live
High-value cohorts, churn-risk users, suppression lists, lookalike seeds — all defined as SQL and synced daily to Meta, Google Ads, Klaviyo, HubSpot, LinkedIn.
Consent State Per Channel
Every profile carries a consent flag per destination. No row leaves the warehouse to a channel the user hasn't consented to. Defensible to regulators, not just compliant on paper.
PII Hashing + Audit Log
PII hashed SHA-256 before leaving the warehouse. Every reverse-ETL sync logged with row counts, consent state, and timestamp — full forensic trail.
Who this is for
E-commerce Brand
You have customers everywhere — Shopify, Klaviyo, Meta, Google Ads, your loyalty platform — and none of them know each other. We build a CDP where every channel sees the same canonical profile, and your activation finally compounds:
- High-value RFM cohorts synced to Meta Custom Audiences and Google Customer Match daily
- Suppression lists (recent buyers, refunders, opt-outs) pushed to every ads platform automatically
- Klaviyo flows triggered from warehouse logic instead of fragile point-and-click rules
- Lookalike seeds built from your actual best customers, not from "anyone who bought once"
Lead Gen / B2B
Your CRM knows which leads become customers — but Google Ads and Meta still optimize on form-fills, which is half-blind. We close the loop with offline conversion uploads, so your bidding learns from revenue, not signals:
- Server-side Lead event fired with full identity → Meta CAPI, Google Ads, LinkedIn Insight CAPI
- Offline conversions: when a lead becomes SQL or Customer in the CRM, the conversion fires back to Google Ads (matched on GCLID) and Meta CAPI (matched on hashed email)
- Bidding algorithms learn from pipeline value, not form-fills — radically better CAC over 90 days
- Account-level firmographic enrichment piped into ABM audiences for LinkedIn
Digital Agency
You manage 8–15 client accounts, each with its own consent regime and its own brand DNA. We build a multi-tenant CDP architecture that scales with your book — defensible, white-label, and fast to onboard new clients:
- One RudderStack instance, isolated workspaces or projects per client — no cross-pollination
- Consent state isolated per brand — each client's data governance is independent and regulator-defensible
- Audience definitions templated and reusable across the agency book
- New client onboarded in days, not months — the architecture is already there
What to expect
0+ → 1
User IDs unified per customer
0%
Data ownership in your warehouse
Daily
Audience sync to every channel
Case Studies
Case study coming soon
Case study coming soon
Frequently Asked Questions
Ready to Own Your Customer Data?
Get a free CDP architecture audit. We'll map your current data flows, identify the lock-in, and show you what a warehouse-first CDP would look like for your business.